June 29, 2026
Pipeline Orchestration: ZenML, Prefect, Airflow, or Build Your Own?
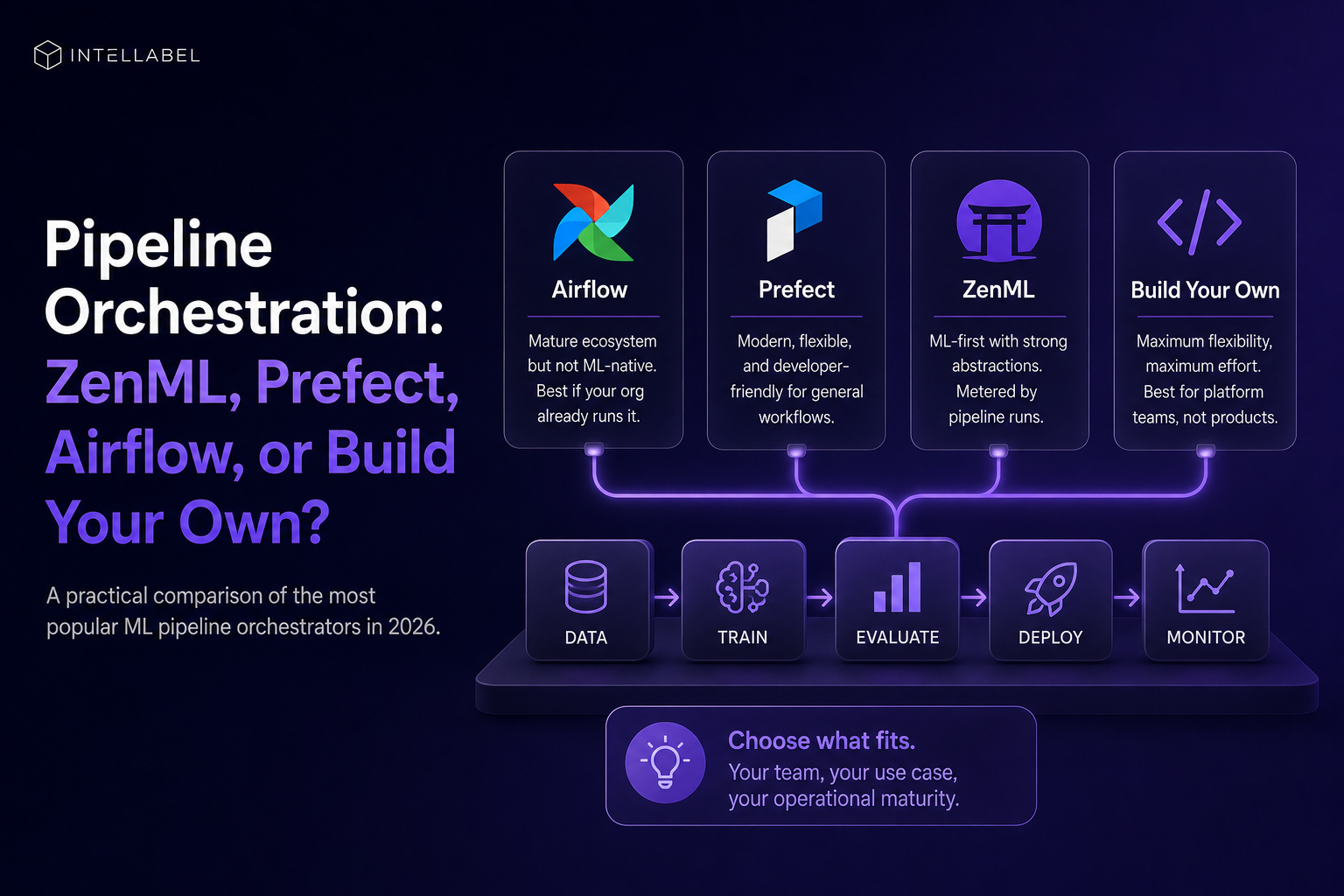
Every ML team picks an orchestrator. Most pick wrong the first time. By project three, they've migrated. By project five, they've migrated again. Here's the comparison framework that should have happened up front.
Airflow: still everywhere, still not great for ML
Airflow runs the world's batch jobs. It also runs a lot of ML pipelines that would be better served by something else. Where it wins: existing organizational adoption, mature ecosystem, every cloud has a managed offering. Where it loses: poor model lineage, no native experiment tracking, DAGs that fail in confusing ways when an upstream task succeeds but produces wrong data.
Use Airflow if your platform team already runs it and you can layer ML-specific tooling on top. Don't adopt Airflow specifically for ML.
Prefect: a better Airflow for general workflows
Prefect rebuilt the orchestration model with modern Python ergonomics. Dynamic DAGs, better failure recovery, cleaner API. Strong for general data engineering. Less specialized for ML — you still bring your own model registry, artifact store, and experiment tracking.
Use Prefect if you want Airflow's job-running with a less painful developer experience and you don't need ML-specific features.
ZenML: ML-first, framework-agnostic
ZenML treats pipelines as ML primitives rather than general workflows. Native concepts for steps, artifacts, model versions, stack components (orchestrator, artifact store, container registry, etc.). Strong abstractions but a learning curve. Pricing is metered by pipeline runs at the lower tiers (500 / 2,000 / 5,000 caps), which scales painfully if your CI runs 50 pipeline executions per push.
Use ZenML if you want ML-first orchestration and you'll commit to its abstractions. Be aware of the runcount meter.
Build your own: usually wrong, occasionally right
Building on top of Argo Workflows, Kubeflow Pipelines, or raw Kubernetes gives you maximum flexibility and maximum maintenance burden. Two engineers permanently allocated to platform work. Use this if you're building MLOps as your product, or if you have requirements no existing tool meets.
It is almost never the right answer for teams whose primary mission is shipping models, not infrastructure.
The decision framework
Three questions in order. First: do you have a platform team with cycles to maintain orchestration infrastructure? If no, go managed. Second: is ML your primary use case, or is orchestration shared with general data pipelines? ML-first means ZenML or an integrated platform; mixed use means Prefect or Airflow. Third: how does the pricing scale with your CI volume? If you do 50+ pipeline executions per push and the tool meters per run, the bill compounds quickly.
Where integrated platforms fit
Intellabel's MLOps and Enterprise tiers include orchestration that runs unlimited within your plan — no perrun meter, no add-on artifact store. The pipelines, model registry, deployment, and monitoring are all in one workspace with a shared audit log. The tradeoff is less framework flexibility than ZenML; the gain is one platform instead of five.
For teams that don't want to assemble the MLOps stack themselves, this is the buy-instead-of-build path. For teams that want maximum flexibility and are willing to operate platform engineering, ZenML or Prefect remain solid choices.
The honest summary
There is no best orchestrator. There is the right orchestrator for your team's makeup, your operational maturity, and your willingness to absorb platform work. Pick once with eyes open, not by browsing GitHub stars.
From Labeling to Structured AI Data Pipelines

Address: WeWork, Salarpuria Symbiosis, Bannerghatta Rd, Bengaluru, Karnataka

.png)