May 25, 2026
Why Your Pre-Trained Model from Hugging Face Is Underperforming on Your Dataset
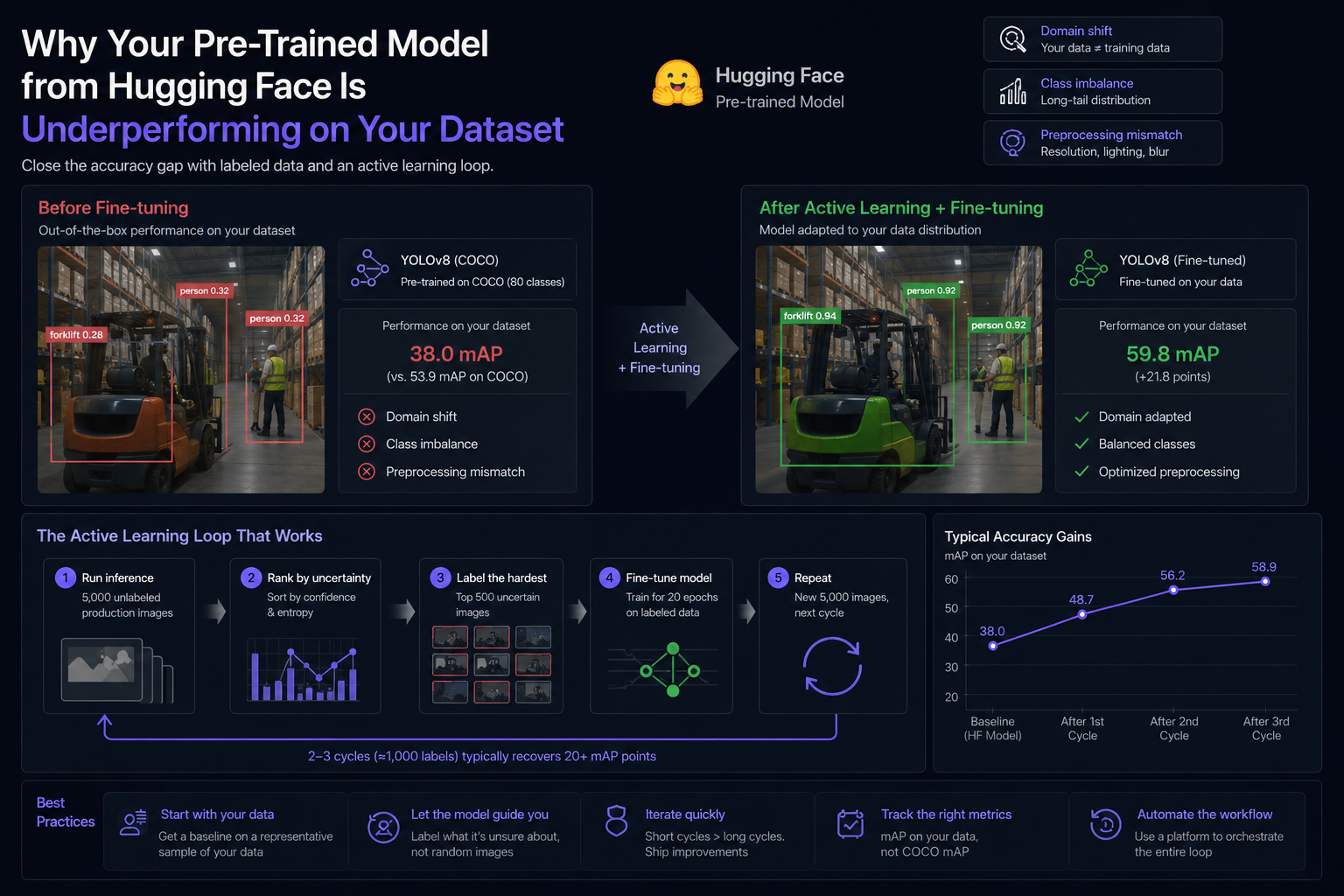
A team imports YOLOv8 from Hugging Face. The model card claims 53.9 mAP on COCO. They run it against their warehouse safety dataset and get 38 mAP. Then they spend two months tuning hyperparameters instead of fixing the actual problem.
The actual problem is that pre-trained models are trained on a distribution that almost never matches yours. Closing that gap takes labeled production data, an active learning loop, and a willingness to let the model tell you which images it doesn't understand
What's actually happening
Three things conspire against you when you drop a Hugging Face model into a new domain. First, domain shift — your warehouse lighting, camera angles, and clutter look nothing like COCO. Second, class imbalance — COCO has 80 well-distributed classes; your dataset has 12 with one class dominating 80% of frames. Third, image preprocessing assumptions — the model was trained at 640×640 with specific augmentation; your camera produces 1080p stills with motion blur.
None of these are exotic problems. They're the default state of every applied computer vision project.
Why hyperparameter tuning won't save you
If your accuracy gap is more than 10 points, no learning rate schedule will close it. You need labeled data from your distribution. Period. Teams burn weeks on Optuna sweeps when the right answer is to label 500 representative images and fine-tune for 20 epochs.
The active learning loop that actually works
The pattern that consistently closes the gap: run the pre-trained model in inference mode against 5,000 of your production images. Sort them by prediction confidence and prediction-entropy disagreement. Take the worst 500. Label those. Fine-tune. Repeat with a fresh 5,000.
Two cycles of this — roughly 1,000 labels — typically recover 20+ accuracy points. Three cycles often gets you within 2 points of what custom training from scratch would produce, at a fraction of the cost.
Where the platform layer matters
The bottleneck isn't usually the labeling — it's the choreography. Importing the HF model, hosting it for inference, running it across thousands of unlabeled images, sorting by uncertainty, routing the hard cases to annotators, retraining, redeploying. Stitching this manually takes longer than the labeling does.
If you're doing this once, a Jupyter notebook works. If you're doing it on a quarterly cadence across multiple models, you need a workflow tool. Intellabel's Growth tier handles BYOM hosting from Hugging Face, active learning loops, and the labeling itself as a single integrated cycle — which is the only way teams sustain this past the first project.
Stop tuning, start labeling
The single highest-leverage habit for an AI engineer in 2026 is to recognize the difference between a hyperparameter problem and a data problem — and to know that the data problem is almost always the one you have. The Hugging Face model is fine. Your data isn't there yet.
Bring your model. Host it for active learning. Label what the model doesn't understand. Fine-tune. Ship.
From Labeling to Structured AI Data Pipelines

Address: WeWork, Salarpuria Symbiosis, Bannerghatta Rd, Bengaluru, Karnataka

.png)