May 04, 2026
Inside Intellabel's Dataset Versioning Engine: Design Decisions & Tradeoffs
Code versioning is a solved problem. Git won. Branch, commit, merge, rebase — we've been doing this for twenty years, and the mental model is universal.
Data versioning is not a solved problem. Not even close. And computer vision data versioning — where your dataset might be ten million images with tens of millions of labels that get edited, re-reviewed, and re-split on a rolling basis — breaks every general-purpose tool in ways that are only obvious once you hit them.
This post is a walkthrough of what we considered, what we chose, and what we'd build differently if we started again. It's aimed at ML engineers and platform leads who are either building their own dataset versioning or trying to understand why the off-the-shelf options keep letting them down.
A note before we start: we're going to be specific about tradeoffs. Some decisions we're confident in. Others we're still actively iterating on. We'll mark which is which. If you're looking for a polished marketing narrative, this isn't it.
What Makes CV Dataset Versioning Hard
Before explaining what we built, it's worth being precise about what problems we were solving. Four of them, specifically.
- Problem 1 — Labels change more than images. In a typical CV pipeline, images are roughly immutable once ingested. But labels are constantly edited: a reviewer corrects a bounding box, a taxonomy update re-classifies an entire category, a new QA stage adds a verification flag. A versioning system that treats images and labels as a single blob forces you to duplicate the image payload every time a label changes. That's unworkable at scale.
- Problem 2 — Partial re-annotation is the norm. You don't re-label the whole dataset. You re-label the hard examples surfaced by active learning, or the edge cases that a model got wrong last week. Your versioning system needs to represent 'dataset V1 plus these 2,000 updated labels' without making a full copy of V1.
- Problem 3 — Experiments branch, and branches need to be cheap. An ML engineer wants to try training with an alternative label schema, or with a subset filtered to a specific camera angle. They need to do this without waiting fifteen minutes for a dataset snapshot to be cloned.
- Problem 4 — Lineage has to survive audits. When something goes wrong in production and a regulator or customer asks 'what data trained this model?' — you need to answer deterministically, six months later, including knowing which reviewer approved each label and what the label schema looked like at training time.
What We Considered (And Why Each Fell Short)
Before building our own layer, we spent serious time evaluating existing options. Here's the honest assessment:
Git-LFS. Solves text-and-binary versioning at small scale. Falls over completely at tens of millions of files. The LFS server becomes the bottleneck, and the mental model of 'commit the whole dataset' is wrong for our use case anyway.
DVC. Legitimately useful for small to mid-size datasets with relatively static labels. Breaks down when labels are churning faster than images, because DVC treats the label file as the versioned artifact — every label edit is a new file, and browsing history becomes painful past a few thousand edits.
LakeFS. Strong on the branch-and-merge semantics we wanted. Real weakness was the coupling to object store semantics — we needed a label-first abstraction, not an object-first one. LakeFS is great if you're versioning at the object store layer; we needed something a layer up.
Delta Lake / Apache Iceberg. Excellent for tabular data versioning. Not the right shape for our access patterns, where a single 'record' is a rich object (image reference + multiple nested annotations + review state + reviewer identity + temporal labels).
Roll our own with Postgres + S3. The path most teams take, and the one we ultimately started from. Works until it doesn't — which is usually around the point where you need cheap branching and efficient diffs.
What We Built
The short version: a label-centric content-addressed versioning layer on top of object-stored images, with copy-on-write semantics for label groups and deterministic fingerprinting for efficient diffs.
Let's unpack that.
Label-centric. The versioning layer doesn't track images and labels together. Images are immutable assets with stable content hashes, stored once. Labels are separately versioned, keyed by (image_id, label_schema_version, label_id). This separation means a label edit doesn't require touching the image payload at all.
Content-addressed. Every label group has a deterministic hash derived from its content. Two datasets with identical labels share the same hash, meaning two 'branches' that happen to produce the same labels are automatically deduplicated. This also makes lineage verification free — you can prove that dataset V3 contains exactly the labels you think it does by checking the hash.
Copy-on-write at the label group level. When a user branches a dataset and edits 500 labels, only those 500 label groups get duplicated in storage. The other 9.5 million label groups in a 10M-label dataset remain shared. Branches become nearly free to create.
Deterministic fingerprinting for diffs. Rather than computing diffs by walking entire datasets, we maintain a Merkle-tree-style structure over label groups. Diffing two dataset versions reduces to walking the tree until you find differing hashes — order-logarithmic in dataset size, not linear.
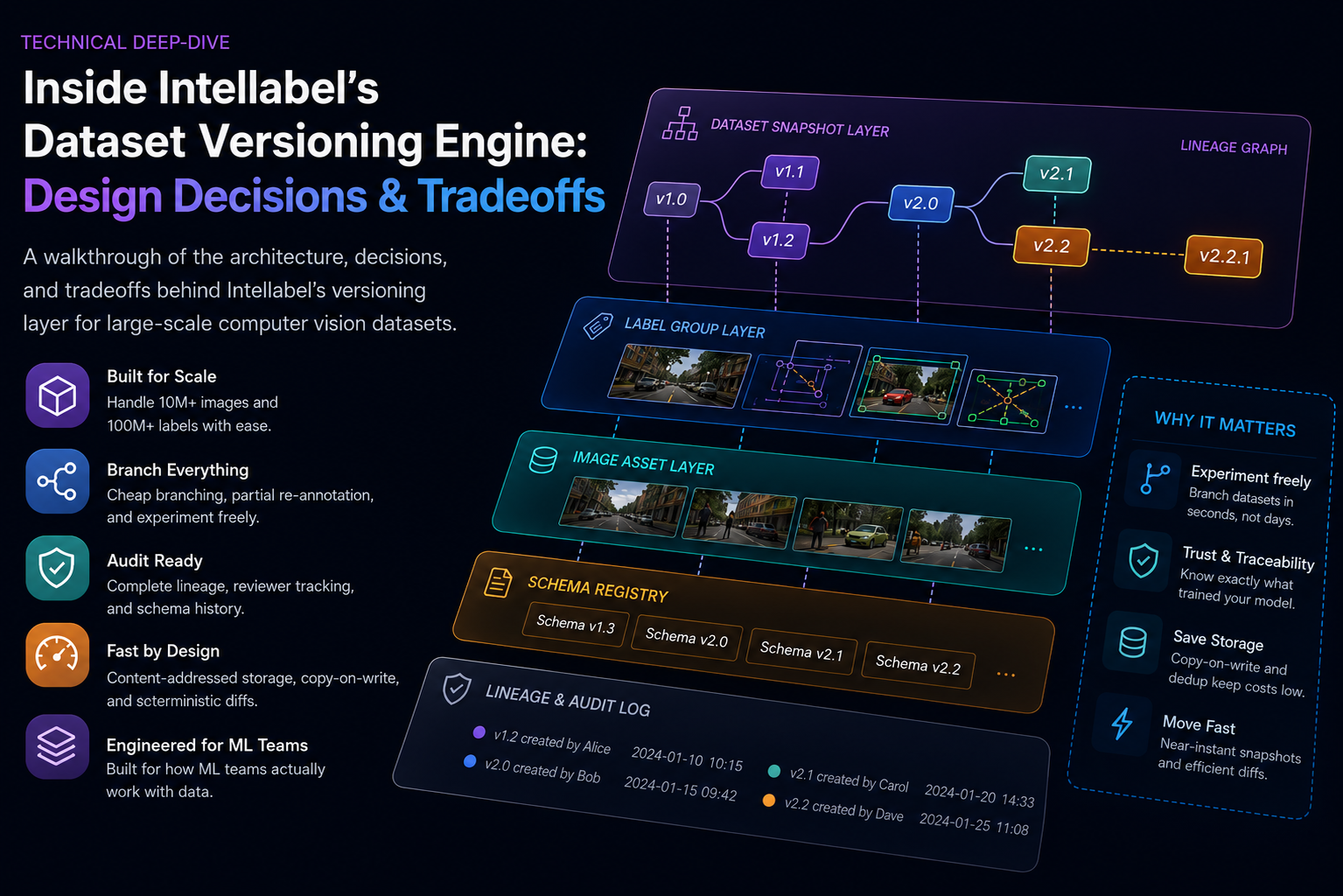
The Architecture, Visually
A simplified view of how the pieces fit together:
Image asset layer. Content-addressed blob storage (S3 or equivalent). One image, one hash, one physical copy, regardless of how many datasets reference it.
Label group layer. Grouping of annotations tied to a specific image under a specific schema version. Content-addressed. Multiple label groups can exist for the same image under different branches.
Dataset snapshot layer. A dataset snapshot is a Merkle tree whose leaves are label group references. Snapshot creation is near-instant — we're building a tree of pointers, not copying data.
Schema registry. Label taxonomies themselves are versioned. When the schema changes, we record the delta, not just the new version. You can always reconstruct 'what did the label schema look like on March 3rd?' which matters enormously for audit scenarios.
Lineage graph. Every snapshot records its parents, its author, its creation timestamp, and the operations applied to produce it. Every training run records the snapshot it consumed. Every production model records the training run it came from. Every production prediction records the model version. The chain is unbroken from a prediction in production back to the specific reviewer who approved the specific label six months earlier.
The Tradeoffs We Made
Every architectural decision has a cost. Here are ours.
We gave up cross-dataset merging semantics. Our model supports branching cleanly, but merging two divergent branches is intentionally manual — we surface conflicts, we don't auto-resolve them. In code, auto-merge is usually safe. In labeled data, auto-merge can silently corrupt your ground truth. We chose correctness over convenience. Some teams see this as a limitation. We see it as a safety feature.
We accepted higher write amplification on schema changes. When a taxonomy update changes how existing labels should be interpreted, we don't rewrite all affected labels automatically. Instead, we create a migration record and let the user decide whether to re-review or auto-migrate. This means a schema change creates bookkeeping. It also means you never wake up to discover your labels were silently rewritten overnight.
We accepted read complexity in exchange for write efficiency. Reading a snapshot means walking the Merkle tree and resolving label group pointers. At scale this would be slow without caching — so we spent engineering effort on aggressive read caching and denormalized materialized views for common query patterns. The system is fast, but the fast path required real investment.
What We'd Build Differently If We Started Today
Three things.
One — we'd invest earlier in the lineage API surface. We built versioning first and lineage second, treating lineage as a natural consequence of versioning. It mostly is, but the query patterns for 'give me everything that produced this prediction' turned out to need their own optimized indices. If we'd known, we'd have designed those indices into the original schema rather than retrofitting.
Two — we'd think harder about label group granularity. We chose 'all labels for one image under one schema' as the unit. For dense segmentation data where a single image has thousands of polygon labels, this unit is too coarse, and edits force too much data movement. For sparse classification data, it's sometimes too fine. We're now iterating toward a dynamic granularity model. If we were starting over, we'd build for that flexibility from day one.
Three — we'd decouple the reviewer identity from the label group earlier. Who reviewed a label is audit-critical but changes less frequently than the label content itself. We initially stored them together and paid the cost of co-updating them. They're now separable, but it's a newer change in the codebase.
Open Questions We're Still Working On
Real engineering posts include what isn't solved yet. In our case:
How to efficiently represent dataset slices for active learning queries. 'Give me the 500 hardest examples in this dataset, given this model's confidence scores' is a core workflow, but storing confidence scores inline inflates label storage. Storing them externally breaks the single-snapshot reproducibility we value. We're prototyping a decoupled prediction store with its own lineage — not yet GA.
How to handle multi-annotator label groups at scale. When three annotators label the same image and we want to keep all three labelings for consensus and disagreement analysis, our current model duplicates the label group structure three times. This is fine at 1M labels. At 50M, it's wasteful. We know we need a better primitive here. We haven't committed to one yet.
How to efficiently support temporal labels for video. A 30-minute video at 30fps is 54,000 frames. Labeling every frame independently loses the structural information that 'these are the same object across frames'. Track-ID-aware versioning at scale is a real open problem in this space, and we're not fully satisfied with our current approach.
Why This Matters in Practice
All of the above is architecture. Here's the user-visible consequence:
An ML engineer at an Intellabel customer can type: 'train a model on dataset production-v4, filter to last quarter's newly-reviewed labels only, use schema version 2.3.' That command runs end-to-end in minutes — not because we're faster than the open-source alternatives at the core operations, but because the versioning layer doesn't require them to assemble a dataset. The dataset is already assembled, the way they described it, at the exact state they specified.
When a production model misbehaves six months later, the same engineer can type: 'show me the 50 training examples most responsible for this prediction's behavior, including their reviewers and original annotation timestamps.' That query runs against the lineage graph. No spreadsheets. No reconstruction.
Data versioning isn't the flashy part of an ML platform. But done badly, it's the layer that quietly makes every other layer unreliable. Done well, it's invisible — and every other layer benefits.
Final Thought
We wrote this post partly to share what we learned, and partly because the industry conversation about dataset versioning is still surprisingly thin. Most companies that solve it solve it privately and don't write about it. If you're working on similar problems, we'd genuinely love to compare notes — drop a comment, email us, or if you want to see the full platform in action, book a technical walkthrough.
The hard part of ML infrastructure isn't the models. It's the plumbing around them. The plumbing is what we work on.
From Labeling to Structured AI Data Pipelines

Address: WeWork, Salarpuria Symbiosis, Bannerghatta Rd, Bengaluru, Karnataka

.png)