May 20, 2026
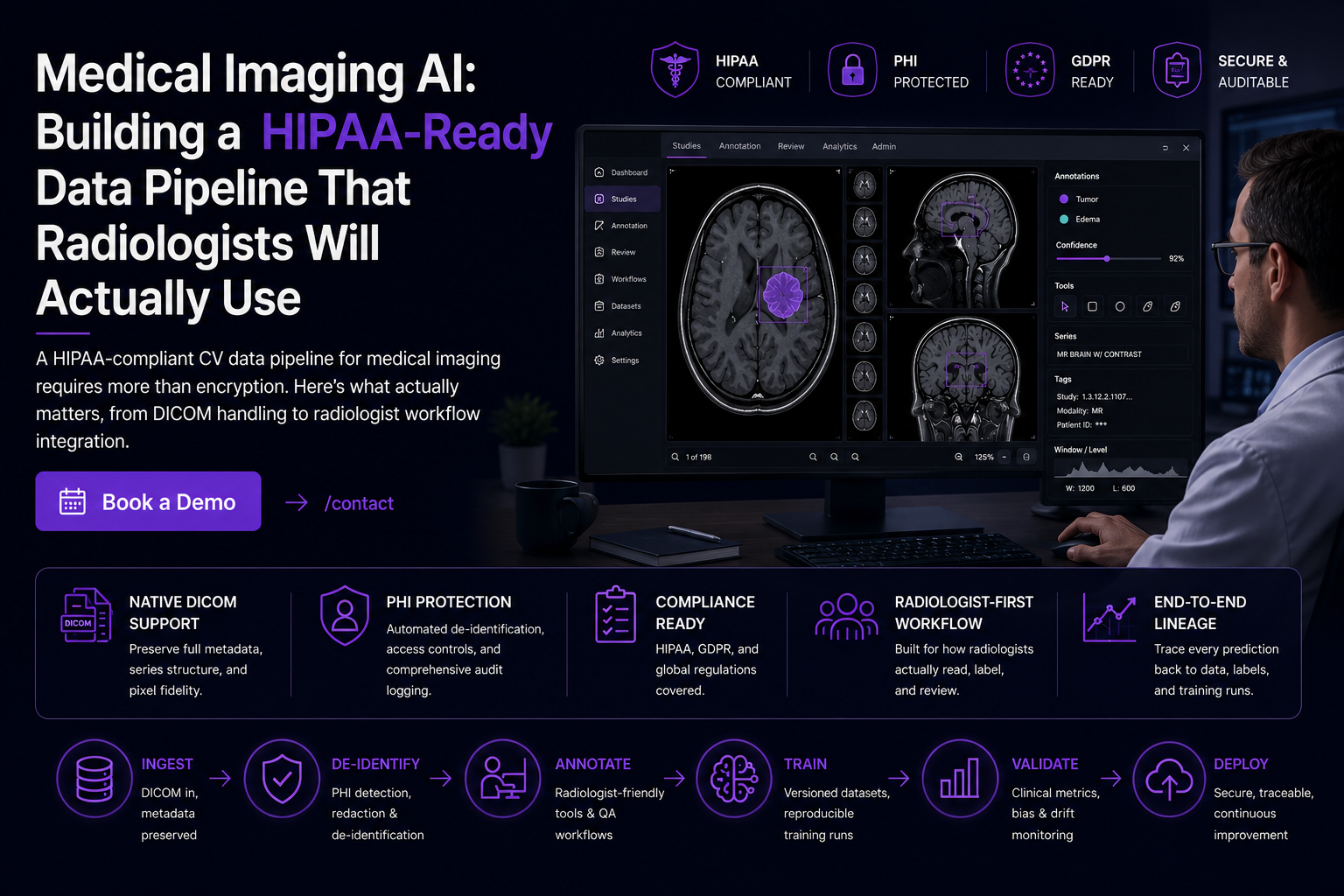
Medical Imaging AI: Building a HIPAA-Ready Data Pipeline That Radiologists Will Actually Use
Medical imaging is the most technically demanding vertical in computer vision, and the one where the gap between 'it works in the lab' and 'radiologists use it daily' is widest.
A capable model is not enough. You need a data pipeline that handles DICOM correctly, manages PHI without silent leakage, passes the compliance audits required to deploy in a hospital, integrates into a radiologist's workflow rather than interrupting it, and can be retrained as imaging protocols and patient populations shift.
This post is for Heads of AI and data operations leaders at health-tech companies building medical imaging AI. We'll walk through what a production-grade pipeline requires, layer by layer, and be specific about where most platforms fall short.
Why Medical Imaging Is Genuinely Different
Before the technical details, a calibration on why this vertical is uniquely hard.
The imagery is not what your pre-trained models saw. General CV foundation models were trained on natural images — photographs of objects and scenes. A chest X-ray, a pathology slide, or a cardiac MRI looks nothing like COCO. Pre-trained representations help less than you'd expect.
The labels require clinical expertise. Your annotators are not a global workforce of generalists. They're radiologists or trained medical imaging specialists, and they're expensive. Your platform needs to respect their time or you won't retain them.
The quality bar is life-or-death. A false negative on a pulmonary nodule is a missed cancer. A false positive is an unnecessary biopsy. The acceptable error profile varies by clinical application, and your pipeline needs to support measuring the right failure modes.
The compliance surface is enormous. HIPAA in the US, GDPR plus various national implementations in the EU, PHIPA in Canada, Australia's Privacy Act, India's DPDP — every jurisdiction has requirements, and your pipeline has to handle all of them.
The regulatory pathway matters. If you're pursuing FDA clearance, CE Mark, or similar clearances, your data pipeline isn't just a production system — it's part of your regulatory submission. Lineage, reproducibility, and audit trails aren't nice-to-haves.
Layer 1 — DICOM Handling, Done Correctly
DICOM is the universal format for medical imaging. It's also one of the most misunderstood file formats in consumer technology, because every 'DICOM support' claim means something different.
Real DICOM support requires: native handling of the full DICOM file structure (not just pixel extraction), preservation of all DICOM tags through your pipeline, correct windowing and pixel value interpretation for each modality (CT, MRI, X-ray, ultrasound all work differently), multi-frame handling for cine DICOM, and support for DICOM series and study structures rather than flat file lists.
What most platforms actually do: convert DICOM to PNG at ingestion and throw away the metadata. This 'works' for prototypes and breaks everywhere else. A platform that loses your DICOM tags loses the patient demographics, the acquisition parameters, the clinical context, the series relationships — all the information that makes a radiologist reading meaningful.
Your data pipeline needs to preserve DICOM natively, including through annotation, storage, training export, and back through inference. Windowing, in particular, needs to happen at display time against the source pixel values, not be baked into a rendered PNG — otherwise your model is training on rendering decisions rather than clinical data.
Layer 2 — PHI Management Beyond Encryption
PHI compliance is often reduced to 'we encrypt everything.' Encryption is necessary and not sufficient.
Real PHI management requires: automated PHI detection and de-identification in DICOM tags (patient name, ID, birthdate, and dozens of other tags), optional automated redaction of burned-in PHI (text rendered into the image itself, common in older systems), access controls that support minimum-necessary access principles, audit trails that log every access to PHI at user-and-record granularity, and retention and deletion policies aligned with your jurisdiction's requirements.
Where platforms most often fail: burned-in PHI. A technician's annotation, a patient ID sticker visible in the field of view, a text overlay from older equipment — these are PHI that no encryption or tag redaction catches. Your pipeline needs either automated OCR-based detection or a strict review step before data enters the training corpus.
Another common failure: PHI leakage through training data. If your training set contains images with identifiable patient features (in some imaging types, patient identity can be inferred from the images themselves), your model effectively memorizes some PHI. This is a research area with no settled solution — but at minimum your platform should support controlled access to raw training data and monitor model outputs for memorization.
Layer 3 — Compliance That Actually Passes an Audit
Having 'HIPAA compliance' on your marketing page is different from passing an actual audit.
What an auditor will look for: BAA coverage for all services touching PHI, including your annotation platform and any cloud infrastructure. Access control documentation showing who can access what. Audit logs covering PHI access, annotation changes, and data exports. Breach notification processes. Employee training records. Regular security reviews. For regulated submissions, full lineage from every prediction back to the training data.
What a platform should provide: signable BAAs (not 'we can discuss it'), SOC 2 Type II attestation, granular role-based access control, immutable audit logs, SSO integration with your identity provider, and region-specific data residency where required (EU data stays in EU, for example).
For GDPR specifically, additional requirements: data minimization (you annotate only what's necessary), right to erasure (a patient can request their data be removed, and you need to actually do this — including from training datasets), data processing agreements with all subprocessors, and explicit legal basis for each data use.
For India's DPDP, Australia's Privacy Act, Singapore's PDPA, and other APAC regulations: data residency within-country is often required for healthcare data, which means your platform needs to offer region-specific deployments.
Layer 4 — Radiologist Workflow Integration
This is where most medical AI projects die, and the reason is almost never technical.
Radiologists have workflows. They use specific PACS viewers, they read volumes at high throughput, and they don't have time to switch into a separate web application to label training data. If your annotation platform forces them to change software, many of them simply won't. You'll get the radiologists desperate for side income, not the ones you want labeling.
What actually works: integrate with their existing viewer through plugins or APIs where possible, mirror their existing keyboard shortcuts and viewing conventions, support multi-monitor layouts the way clinical PACS does, and respect the fact that they think in volumes and series rather than flat images.
Review workflow also matters. Junior radiologist labels, senior radiologist reviews — this is how clinical reads already work, and your QA workflow should mirror it. Two-stage review with disagreement adjudication by a senior reader, time-tracking for honest compensation, and review queues that prioritize by clinical urgency rather than random order.
A platform that makes radiologist labeling a pleasant experience retains its experts. One that doesn't burns through them.
Layer 5 — The Training-to-Deployment Loop
Medical imaging deployments face a specific challenge: you can't deploy a model to a hospital and iterate the way you would for a consumer product. Every change requires validation. Some changes require re-clearance.
Your pipeline needs to support: full lineage from any production prediction back to the exact dataset and training run, reproducibility of training runs with all dependencies versioned, holdout validation against clinically-meaningful benchmarks (not just accuracy — sensitivity, specificity, AUC on relevant subgroups), prospective validation studies where a new model runs in shadow mode alongside an incumbent, and controlled rollout that respects regulatory boundaries.
Drift monitoring in medical imaging deserves special attention. Patient populations shift. Imaging protocols evolve. New equipment is deployed. A model that was 94% sensitive at validation can quietly drop to 88% over 18 months without anyone noticing — until a missed finding causes harm.
A production-grade medical pipeline monitors not just input statistics but clinical outcome correlations where possible. If your model's disagreement rate with reading radiologists starts drifting, that's a signal your pipeline should surface automatically.
What Most Platforms Miss
A summary of the most common gaps we see when teams try to build on general-purpose data platforms:
DICOM handling is shallow. Pixels extracted, metadata lost.
Burned-in PHI is not detected. The pipeline is clean in theory, leaky in practice.
Radiologist UX is an afterthought. Time-per-label doubles compared to what it should be.
Lineage is retrofitted. You can mostly reconstruct what trained what, but not deterministically, not under audit.
Regulatory-grade reproducibility is partial. You can retrain and usually get similar results. Your FDA submission needs 'the same results, always.'
Multi-region data residency is absent. Fine for US-only deployments. Fatal if you're trying to serve EU and APAC hospitals.
These aren't unsolvable problems. They're problems that require the platform to be built with medical imaging as a first-class use case, not as a configuration of a general-purpose tool.
What to Evaluate When Choosing a Platform
For medical imaging AI leaders comparing platforms, this is your shortlist of real questions.
1. Show me a DICOM file going in and coming out of your platform with every tag preserved. Specifically.
2. How do you detect and handle burned-in PHI? Show the workflow.
3. Will you sign a BAA? For what entities? What's covered?
4. Show me the audit log for a single image — who viewed it, who labeled it, who reviewed it, what the label states were at each point.
5. How does a radiologist actually work in this tool? Screenshare a real labeling session with a DICOM series.
6. For a model that's currently in production, show me the dataset version, the training run parameters, and a sample of the labels that most influenced a specific prediction.
7. What are your data residency options for EU, UK, Australia, Singapore, India?
8. Do you have customers pursuing FDA/CE/equivalent clearances, and what artifacts does your platform provide for submission?
The Bottom Line
Medical imaging AI has moved from demo to deployment. The teams that win are the ones with data pipelines that treat regulatory rigor, radiologist workflow, and lineage as first-class concerns — not features to be retrofitted when the FDA auditor arrives.
Intellabel supports DICOM natively, signs BAAs, provides full audit lineage, and integrates into radiologist workflows without forcing context switches. If you're building in this vertical, we'd love to walk you through what a medical-imaging-ready pipeline looks like on your specific clinical use case. Book a demo and we'll set up the conversation with someone who's worked specifically on medical imaging deployments.
From Labeling to Structured AI Data Pipelines

Address: WeWork, Salarpuria Symbiosis, Bannerghatta Rd, Bengaluru, Karnataka

.png)